はじめに
こんにちは。ITエンジニア部の菊田です。 普段はクラウド薬歴サービス「Solamichi」の開発を行っています。
2023年11月14日にAWS にて開催されたBedrockのワークショップ「Amazon Bedrock Prototyping Camp」に参加してきましたので、今回はその内容をご紹介します。
今回はオフライン開催ともあり、アマゾンジャパン目黒オフィスに足を運んできました。
生成系AIやBedrockにご興味がありましたら、是非最後までご一読ください。
Amazon Bedrock Prototyping Campとは
AWSが開催している、Amazon Bedrockを使ってプロトタイプを作成する招待制ワークショップです。
午前は座学・午後はハンズオンを通して、実際にbedrockを取り入れたユースケースを起こしプロトタイプを実装します。 随時AWSの方のサポートを受けながら行うので、困ったときはすぐに質問できる環境がとても良かったです。
内容について
当日のスケジュールはこんな感じでした。

Bedrockについて
Amazon Bedrockは、生成AIのフルマネージド型サービスで、APIを通じて主要な基盤モデルを利用できるようになっています。
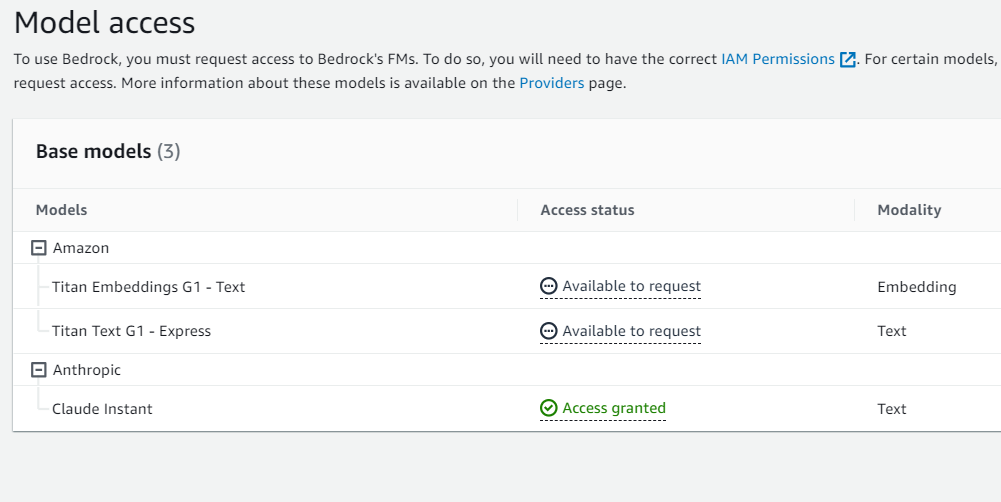
サポートしている主要な基盤モデルは以下の通りです。

現在(2023/12)東京リージョンでは以下モデルが使用可能です。今回のプロトタイピングではClaude Instantを使用しました。
ClaudeモデルはAnthropic(アンソロピック)社がリリースした生成AIです。
最近ではClaude 2.1が正式リリースされ、またGPTよりも精度が高いと話題になっています。
執筆時点(2023年12月)ではAWSでは米国東部 (バージニア北部) および米国西部 (オレゴン)の2リージョンで展開されています。
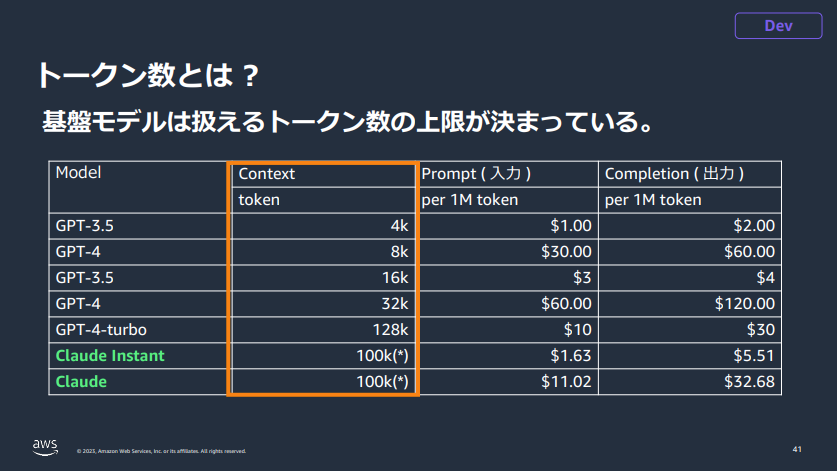
GPTに比べてトークン数が多く、またGPT4に比べて価格が抑えられているのが印象的でした。ある程度の精度や価格面からClaudeモデルはかなり良さそうに感じました。
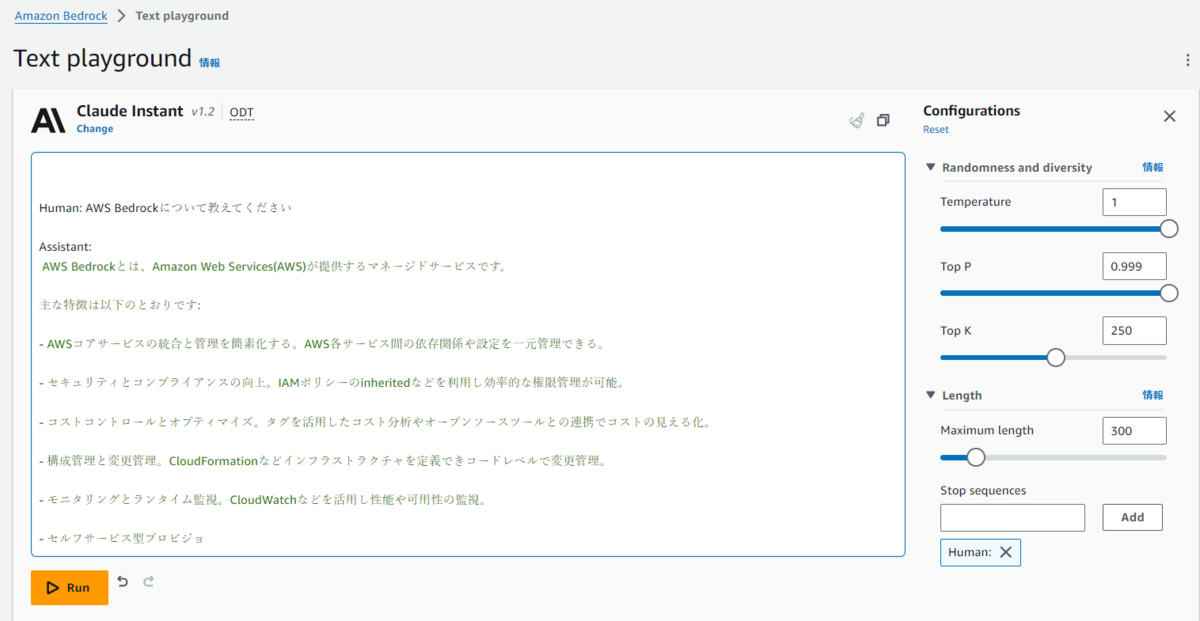
Playground上で各モデルごとのプロンプトやパラメーターを検証することができます。
ChatGPTのような対話形式以外に、Stable Diffusionのような画像生成も行うことができるので、軽く触れてみたい方はぜひ試してみてください。
Kendraについて
Amazon Kendraは、機械学習を活用した検索サービスです。
主な機能としては以下が挙げられます。
- データコネクタ
- インデックス生成
- 検索結果に対する分析・改善ダッシュボード
- MLによる検索精度の向上
また、サポートしているコネクタが豊富でS3やRDSなど様々なデータソースを活用することができます。
Kendraを使うことで、自社で溜まったデータ群をすぐに検索サービスとして立ち上げることができるのは良いですね。
今回のプロトタイピングで触れていますが、Kendraに投入したデータをBedrockに投げて回答を生成するRAGシステムとして使うことができます。
RAGとは
RAG(Retrieval-Augmented Generation)とは、外部のデータソースを生成AIが参照して固有の回答を生成する仕組みです。
KendraとBedrockを組み合わせることで、Bedrockがに投げた質問をKendra側のデータソースを活用して回答することができます。
Prototyping
ワークショップではAWSソリューションアーキテクトの方と相談をしながら、実際にSolamichiに対してBedrockを活用するケースやデータ、アーキテクチャを検討して、開発環境での実装を行いました。
薬歴システムで考えられるユースケースいくつかあったのですが、今回は薬剤情報をベースにしたRAGシステムを実装しました。
実際に作ったモノ
プロトタイピングではフロントの実装が間に合わなかったので、サーバーサイドのみローカルで実装しました。
AWSリソース構成はこんな感じです。
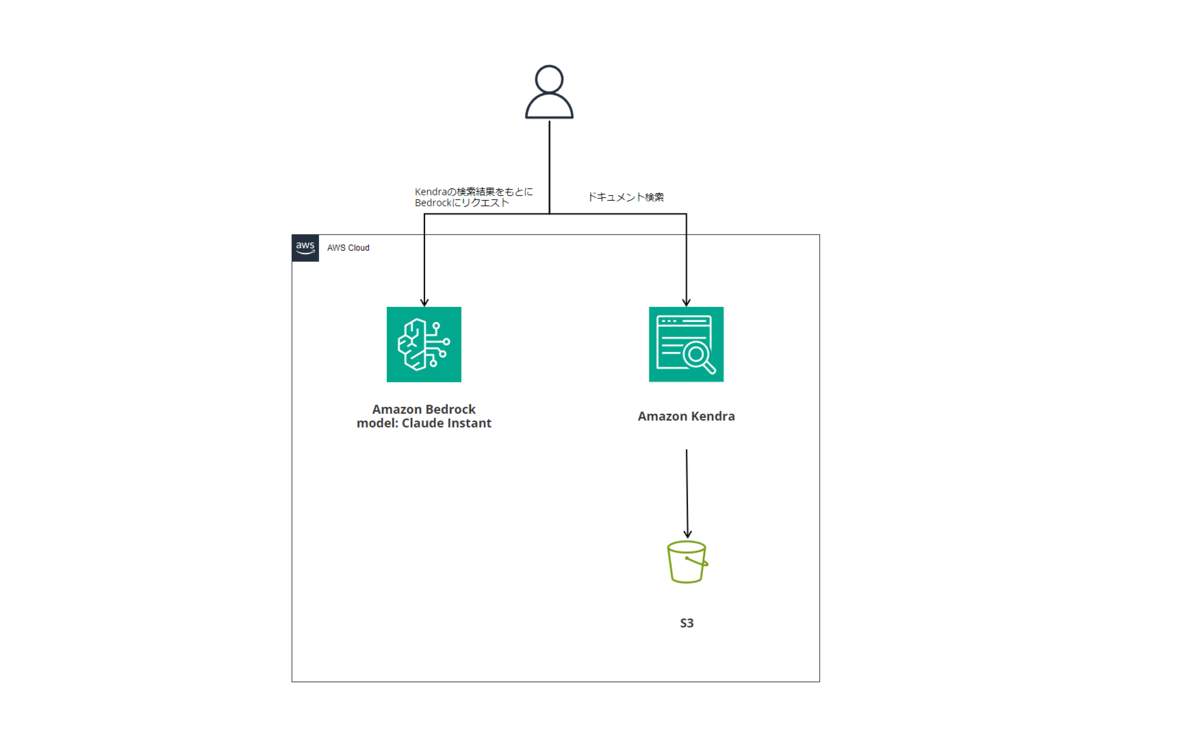
実装は以下内容となります。
import { KendraClient, RetrieveCommand } from "@aws-sdk/client-kendra"; import { BedrockRuntimeClient, InvokeModelCommand } from '@aws-sdk/client-bedrock-runtime' const queryToBedrockAsync = async (prompt: string): Promise<string> => { const client = new BedrockRuntimeClient({ region: "ap-northeast-1" }); const command = new InvokeModelCommand({ modelId: "anthropic.claude-instant-v1", accept: "application/json", body: JSON.stringify({ prompt, temperature: 0.6, top_p: 1, top_k: 250, max_tokens_to_sample: 200, stop_sequences: ['\n\nHuman:'] }), contentType: "application/json" }); const result = await client.send(command); return JSON.parse(Buffer.from(result.body).toString("utf-8")).completion }; const queryToKendraAsync = async (queryText: string): Promise<Array<string>> => { const client = new KendraClient({ region: 'ap-northeast-1' }); const command = new RetrieveCommand({ IndexId: 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', QueryText: queryText, AttributeFilter: { EqualsTo: { Key: '_language_code', Value: { StringValue: 'ja', }, }, }, }); const result = await client.send(command); const contents = result.ResultItems ?.flatMap(item => item.Content ? [item.Content] : []); return contents ?? []; }; const main = async () => { const kendraContents = await queryToKendraAsync('てんかん薬'); const message = `あなたは薬剤師です。以下の薬剤情報を踏まえて、適切な処方を考えてください。回答は以下のJSONで返してください。 <example> { "pharmacist": "こんにちは" } </example>` const medicineInfo = `薬剤情報:${kendraContents.length > 0 ? kendraContents[0] : "なし"}` const prefix = '{' const bedrockContents = await queryToBedrockAsync(`\n\nHuman:${message}${medicineInfo}\n\nAssistant: ${prefix}`); console.log(JSON.parse(prefix + bedrockContents)) }; main();
s3にはKendraデータソース用のバケットを用意しました。データソースは薬剤情報をまとめたPDFを使用しました。
注意点として、Kendraに画像タイプのPDFを読み込ませると、indexing時にテキストデータを読み込めずエラーとなります。
その場合はOCRでテキストデータに変換しておくことをお勧めします。
Bedrockでてんかん薬についての処方を聞いてみると、結果はこんな感じになりました。
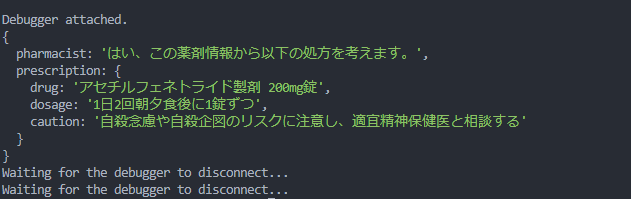
json形式で返却させると、薬剤名や用法をまとめてくれたので、項目をまとめてほしいときはjson形式だと良さそうですね。
情報をPDF側で検索しましたが、ソース情報に則っているのが分かりました。
が、精度がそこまで高い印象ではなく、風邪薬などを聞いてみると睡眠薬の提案をしてきたりします…。
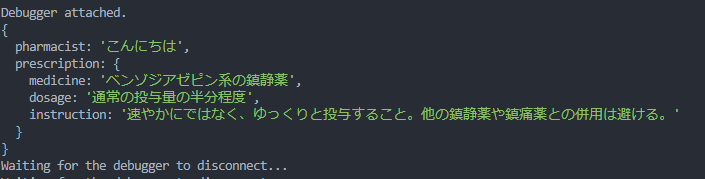
データソースやプロンプトなどに依存しますが、精度がある程度揺らぐので、薬など危険なものや間違えてはいけない案件の例にはあまり向いてないかもしれません(あくまで、「○○にはこんな提案があるよ!」くらいの温度感で聞いた方が良い印象でした)。
所感・その他Tips
KendraのIndexingに結構時間がかかる
Amazon KendraのIndexingには結構時間がかかった印象です。
実装当初は数千件の薬剤PDFをS3に入れましたが、後述する画像PDFのエラーやリトライによりIndexingが半日では終わりませんでした(ほぼこれでワークショップの時間溶けました)。
結局PDFデータは数百件に一度落とし、再度構築し直しました。
画像PDFをKendraで読む場合OCRで変換する
今回はPDFをデータソースとして使用しました。
PDFの中には画像データとして保存されているケースがあり、Kendraで読み込むと空ファイルとみなされエラーとなります。
"IndexingStatus": "DocumentFailedToIndex", "ErrorMessage": "Document cannot be indexed since it contains no text to index and search on. Document must contain some text", "ErrorCode": "400"
KendraでPDFを使う場合はOCRでテキストファイルに変換して読み込ませる必要があります。
プロンプトの日本語設定
これはKendra設定後に詰まったポイントですが、リクエストを投げる際は言語設定が必要です。
デフォルトだと英語になっているので、日本語でリクエストする際は言語設定の指定を忘れずにしましょう。
まとめ
今回はAmazon Bedrock Prototyping Campに参加してきました。
BedrockやKendraの基本的な使い方や、生成AIについての理解を深めることができ、とても充実したワークショップでした。
AWS re:Invent 2023でBedrockについてのアップデート情報もたくさんありました。まだ触れていない機能についても今後触っていきたいと思います。
この度は、素敵な機会を作っていただいたAWSスタッフの方々ありがとうございました。